What is data annotation and why does it matter?
Daily life is guided by algorithms. Even the simplest decisions — an estimated time of arrival from a GPS app or the next song in the streaming queue — can filter through artificial intelligence and machine learning (ML) algorithms. We rely on these algorithms for a number of different reasons which include personalization and efficiency. But their ability to deliver on these promises is dependent on data annotation: The process of accurately labeling datasets to train artificial intelligence to make future decisions. Data annotation is the workhorse behind our algorithm-driven world.
What is data annotation?
Computers can’t process visual information the way human brains do: A computer needs to be told what it’s interpreting and provided with context in order to make decisions. Data annotation, the task of adding metadata tags to the elements of a dataset, makes those connections. It adds a layer of rich information to support the ML process by labeling content such as text, audio, images and video so it can be recognized by models and used to make predictions.
Data annotation is both a critical and impressive feat when you consider the current rate of data creation. According to Statista, in 2020, 64.2 zettabytes of data was produced. By 2025, that number is projected to grow to more than 180 zettabytes. For these massive amounts of data to be useful, they have to be transformed into data intelligence. This is done using machine learning tools, which analyze and transform large datasets into insights that can be easily understood and used to help businesses and organizations make decisions more efficiently and effectively. Data annotation is a key part of this process.
The importance of data annotation
Data is the backbone of the customer experience. How well you know your clients directly impacts the quality of their experiences. As brands gather more and more insight on their customers, AI can help make the data collected actionable.
Data annotation is an essential part of this process. In order to train the model, large amounts of data need to be accurately labeled. Doing so creates a ground truth dataset that serves as the basis for teaching the algorithms how to interpret new data. The benefit is that these ML algorithms can identify patterns, correlations and anomalies in the data much more quickly than human analysts, and also at scale. This business intelligence can be used to provide personalized product and service recommendations, develop more engaging customer surveys, enable self-service rates, help identify pain points in order to boost customer retention and more.
As it currently stands, data scientists spend a significant portion of their time preparing data, according to a survey by data science platform Anaconda. Part of that is spent fixing or discarding anomalous/non-standard pieces of data and making sure measurements are accurate. These are vital tasks, given that algorithms rely heavily on understanding patterns in order to make decisions, and that faulty data can translate into biases and poor predictions by AI.
Data annotation best practices
Using high-quality training datasets is critical to the performance of your ML models, and the quality of the training data is reliant on accurate annotation. Here are several best practices to consider for any annotation project.
1. Create annotation guidelines
Even a seemingly straightforward annotation task can potentially cause confusion. This can be resolved by having a comprehensive set of well-written instructions. These guidelines should provide descriptions of individual annotator tasks and information that can help annotators understand the project’s use case. It should also clearly identify edge cases and how to handle them. Throughout the guidelines, examples should be included.
2. Develop golden standards
The golden standard dataset serves as a living example of the annotation guidelines and is often compiled by one of the team’s data scientists who understands exactly what the data needs to achieve. It reflects the ideal labeled dataset for your task and can serve as an objective measure for evaluating your team's accuracy in terms of performance.
3. Avoid using too many labels
Having to choose from too many labels can negatively impact overall annotation quality as it can lead to indecision and confusion among your annotators. For example, labeling an animal simply as “Dog” is far simpler than having to select from the different breeds, such as “Dog-German Shepherd”, “Dog-Poodle”, “Dog-Boston Terrier”. Keeping the number of possible labels to a smaller set leads to more reliable results.
4. Measure annotation accuracy regularly
To ensure data annotation accuracy, you need to be able to measure it. This is usually done by assessing the degree of agreement between annotators. Inter-annotator agreement measures how many times annotators make the same annotation decision for a certain category. It can be calculated for the entire dataset, between annotators, between labels or on a per-task basis using a variety of metrics.
5. Hire a diverse team
Data bias in ML occurs when the model is trained on datasets that are skewed or don’t fully represent the groups the model intends to serve. This impacts the model’s accuracy level and can actually harm the humans using it.
Although it’s difficult to avoid bias in your datasets entirely, one way to mitigate it is by hiring a diverse team of annotators who bring a wide range of perspectives.
6. Monitor and adjust your process as needed
Throughout the annotation process, you’re bound to come across issues that need to be resolved. This could be anything from new edge cases to a lack of clarity between labels to the quality (or lack thereof) of your raw data. It’s important to quickly resolve these issues to ensure the ongoing quality of your training dataset. Once resolved, you should update your golden standards to reflect these changes.
7. Ensure data privacy and security
It’s important to consider privacy and ethical issues when annotating datasets containing personal identifiable information (PII) such as images featuring people, names, addresses, social security information, health records and more. Be sure to take the necessary steps to secure this data. Ways to do so include having annotators sign non-disclosure agreements, ensuring your organization is SOC-certified and using an annotation platform that auto-anonymizes images.
Types of data annotation
Data annotation is a broad practice but every type of data has a labeling process associated with it. Here are some of the most common types:
- Text annotation: With this type of annotation, labels are assigned to a text document or different parts of its content to identify sentence characteristics. Types of text annotation include entity tagging, sentiment labeling and parts-of-speech tagging. For example, text annotation is used to train the natural language processing algorithms behind chatbots.
- Semantic annotation: Semantic annotation is a process where concepts like people, places or company names are labeled within a text to help machine learning models categorize new concepts in future texts. This is a key part of AI training to improve chatbots and search relevance.
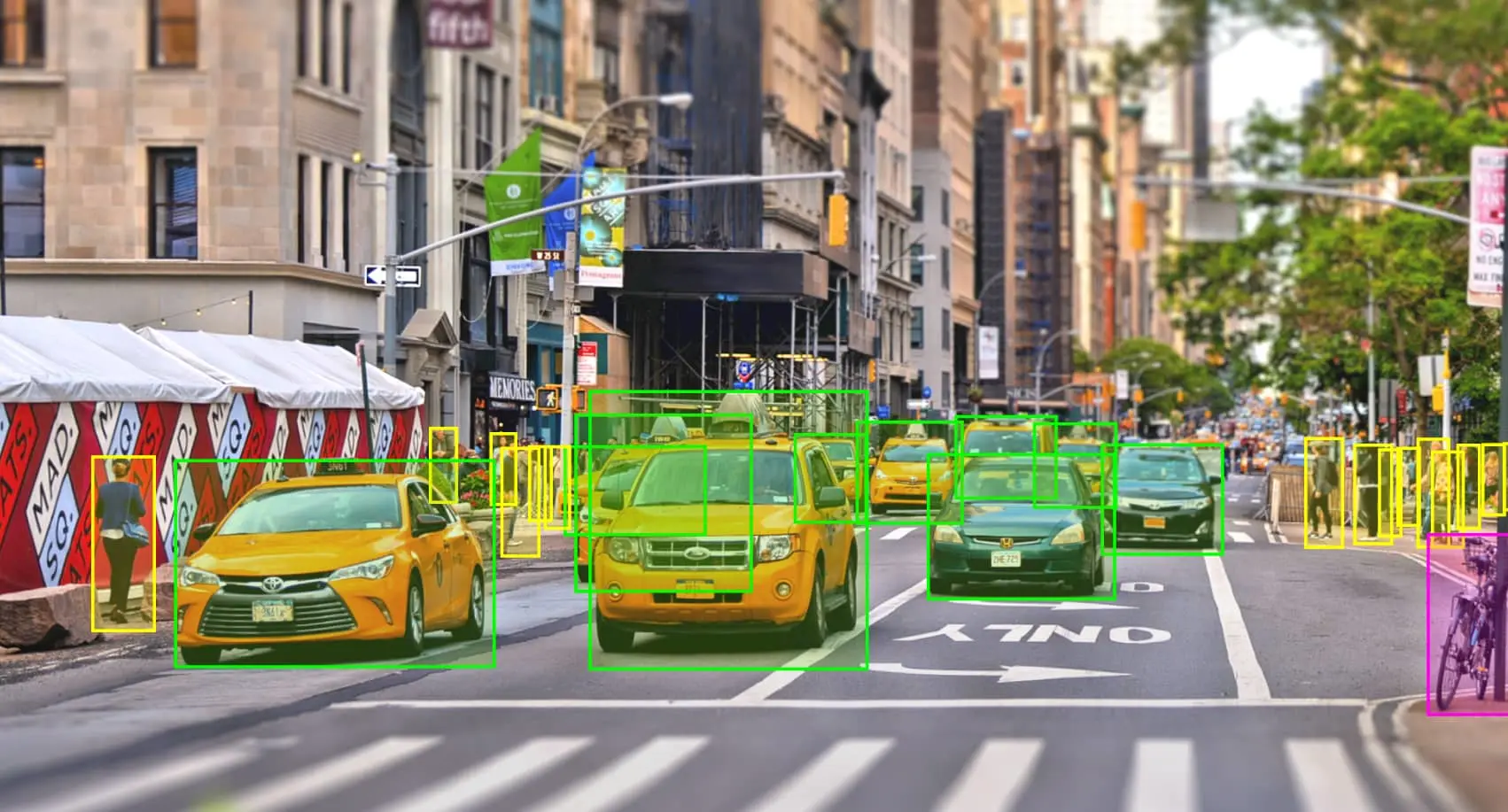
- Image annotation: This type of annotation ensures that machines recognize an annotated area as a distinct object and often involves bounding boxes (imaginary boxes drawn on an image) and semantic segmentation (the assignment of meaning to every pixel). These labeled datasets can be used to guide autonomous vehicles or as part of facial recognition software.
- Video annotation: Similar to image annotation, video annotation uses techniques like bounding boxes but on a frame-by-frame bases, or via a video annotation tool, to acknowledge movement. Data uncovered through video annotation is key for computer vision models that conduct localization and object tracking.
- Audio classification: This process involves classifying audio samples into different categories, including speech, music, environmental sounds and more. Speech classification is commonly used for training virtual assistants.
- Text categorization: Text categorization is the process of assigning categories to sentences or paragraphs by topic, within a given document. An example of text categorization is email spam filtering, where messages are classified into the categories of spam and non-spam.
- Entity annotation: This is the process of helping a machine to understand unstructured sentences. There are a wide variety of techniques that can be utilized to establish a greater understanding such as Named Entity Recognition (NER), where words within a body of text are annotated with predetermined categories (e.g., person, place or thing). Another example is entity linking, where parts of a text (e.g., a company and the place where it’s headquartered) are tagged as related.
- Intent extraction: Intent extraction is the process of labeling phrases or sentences with intent in order to build a library of ways people use certain verbiage. For example, “How do I make a reservation?” and “Can I confirm my reservation,” both contain the same keyword, but have different intent. It’s another key tool for teaching chatbot algorithms to make decisions about customer requests.
- Phrase chunking: Phrase chunking involves tagging parts of speech with its grammatical definition (e.g., noun or verb). Chunking is important to natural language processing (NLP) because it breaks down large strings of data into units, helping to narrow down the amount of information that needs to be processed.
Data annotation use cases
Data annotation can be applied to a number of domains. Common industry use cases include the following:
- Automotive: To ensure their safe operation, autonomous vehicles have to be able to perceive their surroundings. Image annotation done with bounding boxes is used to train self-driving cars by serving as a point of reference for them to avoid.
- Ecommerce: Products and services are annotated in order to ensure relevant search engine results and product recommendations.
- Customer service: Annotated data can be used by businesses to analyze the underlying sentiment of customer messages (emails, reviews, social media comments) into positive, negative or neutral categories. This helps to determine how the messages should be triaged.
- Healthcare: Medical data annotation involves adding additional information to x-rays, computerized tomography (CT) scans, ultrasounds, magnetic resonance imaging (MRIs) and more in order to improve accuracy. This information can also help train ML models to identify and analyze medical conditions.
- Insurance: Annotation can be used to build algorithms that accurately assess risk in order to determine insurance premiums and to expedite the claims process.
- Agriculture: Annotated images or video can be used to help in the detection of crop diseases, identify pests and estimate yields.
- Finance: Use cases include customer payment predictions, credit risk assessment and management and regulatory compliance, to name a few.
- Hospitality: Data annotation can help the hospitality industry in a number of ways, including keeping track of food and beverage sales and inventory levels, offering personalized customer recommendations, predicting demand and scheduling staff.
Main challenges of data annotation
Annotating large amounts of data can inevitably present some obstacles. The following are a few of the most common data annotation challenges you’re likely to encounter.
- Data volume: The sheer volume of data required to train AI models can present a challenge in terms of resources, as many organizations simply don’t have the team members needed to handle high-volume labeling.
- Quality: Concerns around quality are compounded by high data volume and speed of production requirements. Relying only on human annotators to complete complex annotation tasks can slow down your data supply chain and project delivery.
- Consistency: It’s essential that your annotators maintain a consistent approach to ensure high data quality. It’s also often the biggest challenge when undertaking a large annotation project. As a result, any inconsistencies must be addressed as soon as they are identified.
- Bias: AI bias occurs when an algorithm produces output that is prejudiced because of inaccurate assumptions made during the ML process. There are some bias types that your annotators may not even be aware of. An example is anchoring bias, which is a tendency to base opinions on the first similar piece of data experienced, which can cloud objectivity.
- Budget: A data annotation project is often a lengthy process. From the start, organizations need to account for this and structure their budgets accordingly.
- Tools and technology: Data annotation projects are often too large to be handled by human resources alone. Many projects require automation tools and techniques. It’s critical to implement the appropriate technology to ensure the highest quality annotated data.
An evolving science
In the same way that data is constantly evolving, the process of data annotation is becoming more sophisticated. To put it in perspective, several years ago, it was enough to label a few points on a face and create an AI prototype based on that information. Now, there can be as many as 20 dots on the lips alone.
The ongoing transition from scripted chatbots to chatbots powered by generative AI is one of the frontrunners promising to bridge the gap between artificial and natural interactions. Algorithms will continue to shape consumer experience for the foreseeable future — but algorithms can be flawed, and can suffer from the same biases of their creators.
Ensuring AI-powered experiences are pleasant, efficient, effective and accurate requires data annotation done by diversified teams with a nuanced understanding of what they’re annotating. Only then can we ensure data-based solutions are as accurate and representative as possible.
When it comes to your data needs, working with an experienced AI data solution provider can help. To learn more about TELUS Digital’s end-to-end solutions for machine learning, reach out today.