
Video annotations help machines recognize objects and distinguish them from their surroundings. The objects are annotated across a series of frames to help accurately determine motions and movements, all with the goal of enhancing machine learning (ML) models for computer vision.
Video annotation has widespread applications across industries, the most common being autonomous driving perception, human activity or pose points tracking for sports analytics and facial emotion recognition.
In this article, we dive into video annotations — the different types and popular applications. Throughout, we highlight the benefits of labeling automation in the video annotation process.
What is video annotation?
Video annotation is the process of enriching video data by adding object information tags across every frame to detect motion or movement. Video annotations help machines interpret or see the world around them more accurately and are used to train algorithms for a variety of tasks. For example, metatags on frames inform video frame classification, and bounding boxes or polylines support object detection and tracking.
Machine learning engineers predetermine all critical parameters that affect the model’s outcomes to ensure the frames have the accurate information required to train the ML models. For example, training a perception model to identify the movement of pedestrians on a crosswalk requires data that spans across multiple frames that accurately record pedestrian movements in different crossing scenarios.
Types of video annotations
Commonly used video annotations include 2D bounding boxes, 3D cuboids, landmarks, polylines and polygons.
2D bounding boxes
Bounding boxes are rectangular boxes commonly used for object detection, or localization and classification in a few cases. Annotators draw these boxes manually around objects of interest in motion across multiple frames. The box should accurately encase the object (i.e. the boundaries must be as close to every edge of the object as possible). The object class and any attributes must accurately represent the object and its movement in each frame.

2D bounding box annotations to identify objects and track movement across frames
3D cuboids/bounding boxes
3D cuboids label the length, width and approximate depth of an object in motion for a more accurate 3D representation of an object and how it interacts with its surroundings. It allows the algorithm to distinguish features like volume and position of an object in the three-dimensional space with its movements. Annotators draw a box around the object of interest and place its anchor points at its edges to indicate depth. If the edges are blocked or out of view in the frame, the annotator approximates them based on the size and height of the object and the angle of the frame.

3D bounding boxes to detect and track vehicles moving across frames.
Polygons
Polygons replace 2D or 3D bounding boxes when a bounding box can’t accurately represent an object’s shape or motion, for instance, in cases where the shapes and forms are irregular. Polygon annotations usually require a high level of precision from the labeler. The annotators draw lines by accurately placing dots around the outer edge of the object they want to annotate.

Polygon annotation to detect and track pedestrian crossing a road for autonomous vehicle use case.
Keypoints and landmarks
Keypoint and landmark annotations detect small objects and shape variations. They include dots across the image and lines connecting those dots to form a skeleton of the object of interest across each frame. It is commonly used for detecting facial features, expressions, emotions and human body movements, and it is technique with applications in AR/VR, sports analytics and facial recognition.

Landmark annotations to accurately track human pose points for sports analytics.
Lines and splines
Lines and splines help to train machines to recognize lanes and boundaries, especially in the autonomous driving industry. The annotators draw lines along area boundaries that the algorithm must recognize across frames.
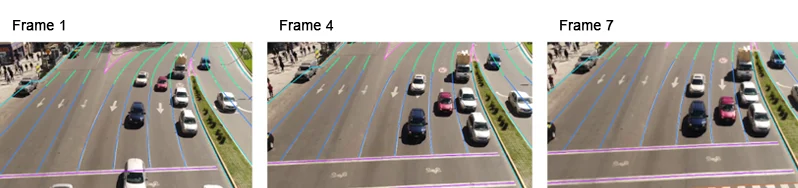
Polyline annotation to detect lane lines for autonomous driving.
Popular computer vision applications using video annotations
Video annotations facilitate accurate 2D and 3D object detection, localization, tracking and classification to improve visual intelligence for computer vision models.
Autonomous vehicles
The autonomous driving industry is by far the most reliant on video annotations. Companies building L4 and L5 autonomous vehicles need to use thousands of hours of videos that span across multiple cities, weather conditions and real-world scenarios to enhance mobility functions. For instance, advanced automotive perception models detect and track cars and motions with unique object IDs across 3D frames collected via lidars.
Here’s another sample of how video annotation via 2D bounding boxes tracks movements of cars at an intersection and oncoming vehicles across multiple frames of a video.
In most cases, machine learning models use sensor fusion video datasets collected via multiple cameras and lidar sensors for more specific object detection and tracking. Here, we start by tagging, detecting and tracking objects of interest in 2D and 3D scenes. From there, we assign unique tracking IDs to identify and link each object across both the scenarios in all frames.
Autonomous driving applications also use polylines to detect lane lines and road crossing signs that help autonomous vehicles perceive drivable areas.
Video frames classification is used in automotive perception models to classify frames into broad categories based on their contents. It is advantageous for extracting abstract information like scene detection, weather or time of day. The video sample below contains time stamped tags for attributes like daytime/nighttime, the weather, environment, object occlusion, etc.
More recently, governments around the globe have mandated the use of advanced driver assistance systems (ADAS) and driver monitoring systems (DMS) in cars to improve road safety. These systems rely heavily on video datasets to train computer vision-based models that track human activities and estimate their poses. In the following video, notice how landmarks trace the driver’s movements to detect any signs of drowsiness or inattention while driving.
Augmented and virtual reality
Video annotations capture the object of interest frame-by-frame, making it recognizable to machines. In the sample below, 3D cuboid annotations detect and track the mirror, plants, bookshelves, couch cushions and chairs across multiple frames in an interior setup to enhance perception for augmented or virtual reality (AR/VR) models.
Sports analytics
Another popular application of video annotation includes human pose-point estimation via landmarks. For sports analytics, these models track all the actions athletes perform during competitions or sporting events to help machine learning models estimate precise human poses.
In the retail industry, video annotation enables object detection and localization to track buyer behavior. Other retail applications include stock replenishment models, store planning models and customer experience (CX) models. The example below showcases classes like shoppers, store assistants, stationary store objects and price tags, all tracked across multiple frames.
Surveillance
Another popular application includes surveillance. In the footage below, precise object detection allows airport surveillance models to identify suspicious activities for improved public safety.
Faster video annotations via labeling automation
Executing accurate video annotations is a labor-intensive process because human annotators have to annotate each frame accurately to help build training datasets for machine learning algorithms. And with videos, the number of frames can quickly add up to millions. That’s why labeling automation becomes indispensable for building video datasets faster.
TELUS Digital’s AI Training Data Platform offers ML-assisted labeling automation features like interpolation and ML proposals to enable faster and more accurate annotations.
Interpolation is an automation feature that significantly simplifies video annotations. Commonly used to label objects in a sequence, the interpolation feature allows the annotator to label every second to the fifth frame in a video sequence. Consequently, this feature drastically reduces video labeling time because the annotators are not required to annotate the same object across all video frames.
Further, the ML proposals function can auto-detect up to 80 general classes across different use cases to help annotators validate labels instead of creating them from scratch.
Here’s a short demonstration of these automation features in action.
Looking to annotate video data? Reach out to our experts to learn how we can help you create high-quality labeled data at faster speed and scale.



