Many factors can impact the development of an artificial intelligence (AI) model, but data quality is unquestionably the most central to its success. If you use poor-quality training datasets, your models will yield less meaningful results, which could delay or derail your AI development efforts.
The data processing steps include sourcing, engineering (aggregating and cleaning), annotating (or labeling) and validating. Data annotation, in particular, is integral to machine learning initiatives because it teaches the model how to produce more accurate outcomes. Annotation refers to any metadata tag used to mark up elements of a dataset and provide a layer of rich information to support machine learning.
To ensure data annotation accuracy, you need to be able to measure it. This can be done by assessing the degree of inter-annotator agreement (IAA), which measures how many times the annotators labeling your dataset make the same annotation decision for a certain category. It can be calculated for the entire dataset, between annotators, between labels or on a per-task basis.
There are a number of metrics that can be used to measure IAA precision. In this article, we'll look at four of the most common ones: Cohen's kappa, Fleiss' kappa, Krippendorf's alpha and F1 score.
Cohen's kappa
Cohen's kappa is a quantitative measure of agreement between two annotators labeling the same item. It is considered to be more robust than other measurements (for example, percent agreement) because it takes chance agreement into account.
The formula is calculated as follows, where Pr(a) is predicted agreement among annotators and Pr(e) is the expected agreement among annotators:
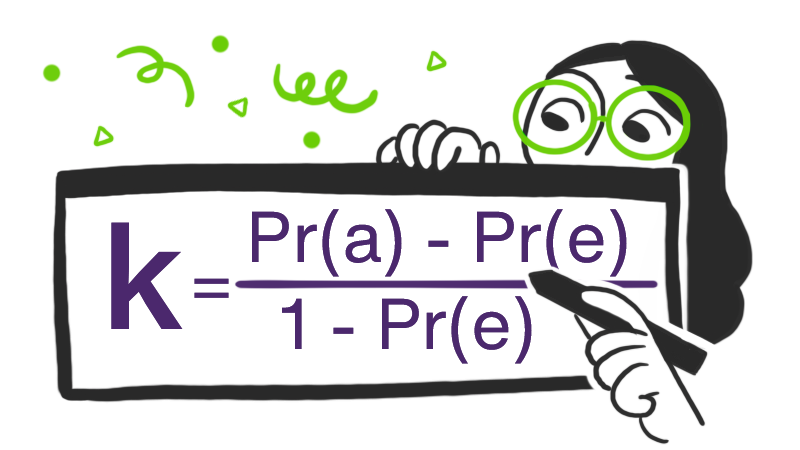
Cohen's kappa statistic varies from 0 to 1, where 0 is no agreement, and 1 is complete or perfect agreement.
A limitation of using Cohen's kappa is that it measures accuracy between only two annotators.
Fleiss' kappa
If you're measuring reliability of agreement between a fixed number of annotators, consider using Fleiss' kappa. Similar to Cohen's metric, Fleiss' ranges from 0 to 1, where 0 is equal to no agreement and 1 is equal to perfect agreement.
The formula for calculating Fleiss' kappa is as follows, where P is the observed annotator agreement and Pe is the expected annotator agreement:
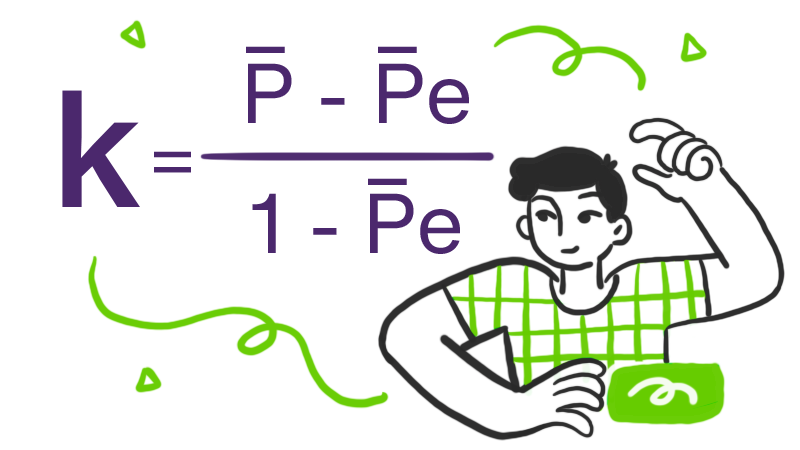
When considering which metric to use, keep in mind that both the Cohen and Fleiss coefficients are subject to the kappa paradox. This is a complex phenomenon where, under certain conditions, the statistic assumes a low value (indicating less agreement) even when there is actually high inter-annotator agreement.
Krippendorf's alpha
As compared to the kappa coefficients, Krippendorf's alpha can be used to calculate inter-annotator reliability for incomplete data and can also account for scenarios in which annotators only partially agree.
Again, values range from 0 to 1, where 0 is perfect disagreement and 1 is perfect agreement. The formula is calculated as follows, with pa being the observed weighted percent of agreement and pe being the chance weighted percent of agreement:
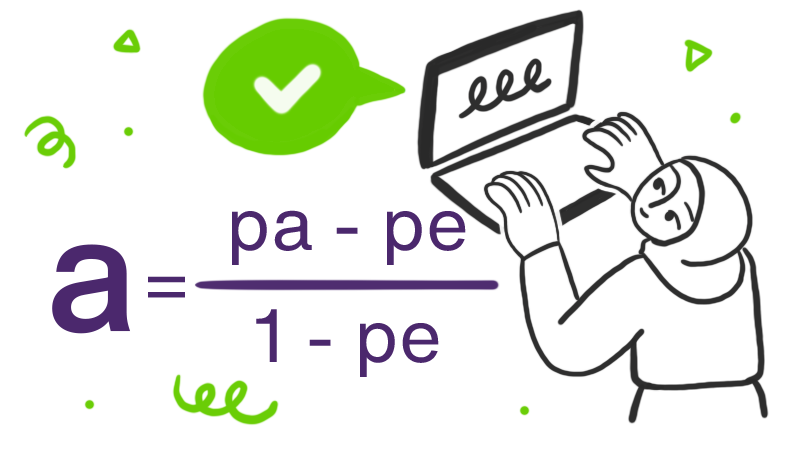
Keep in mind that as compared to the kappa coefficients, this metric is considered to be more difficult to compute. However, it's also considered by many to be more reliable.
F1 score
This metric considers both precision and recall to compute a score from 0 to 1, where 1 indicates perfect precision and recall, and 0 indicates a lack of precision and recall. Measuring precision indicates how many annotations are correct, whereas measuring recall indicates the number of correct annotations compared to the number that were missed. The harmonic mean of these two calculations equates to the F1 score. The closer the F1 score is to 1, the more accurate the model is considered to be.
The formula is calculated as follows:
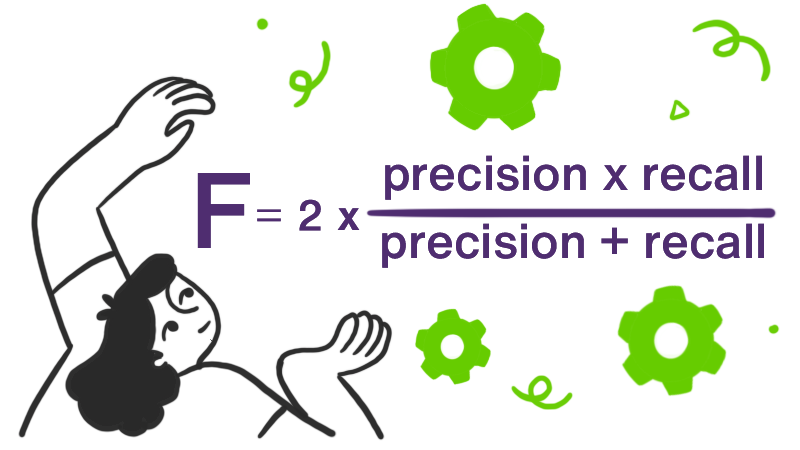
It's important to keep in mind that as compared to the other metrics outlined, F1 score doesn't take expected chance agreements into account.
Best practices for data annotation accuracy
Ensuring data annotation accuracy starts with hiring experienced annotators and providing robust training, using a combination of automated and manual quality checks and establishing feedback processes. Additional best practices to consider, include:
Define what a high-quality deliverable looks like to you
The best way to receive high-quality annotations is to have a clear vision of how you want them to look. Before determining this, be sure to take both the amount of time you have designated for your project and your budgetary constraints into consideration.
Project length
When determining the length of your project, consider how it will impact annotation quality. In general, the longer a project goes on, the more experienced and accurate the annotators become. Of course the budget will impact project length, but it is something to consider when determining the level of accuracy you want to achieve.
Budget
Accounting for budgetary constraints and how these will impact the quality of your datasets is imperative. Consider how accurate your data actually needs to be. For example, is your task labeling objective truth, or are you looking for subjective answers from a range of annotations?
Establish golden standards
Usually compiled by one of your data scientists who understands exactly what the data needs to achieve, ground truth data reflects the ideal labeled dataset for your task and serves as a living example of the annotation guidelines. It also provides you with an objective measure for evaluating your team's performance for accuracy. Further, it can be used as a test dataset to screen annotation candidates.
Enhancing the data annotation process through partnership
By working with a data annotation provider, you are able to leverage the invaluable expertise and resources of an established partner. The right company can provide the raw data itself, a platform for labeling the data and a trained workforce to accurately annotate hundreds of thousands of data points at scale. Learn more about TELUS Digital's AI Data Solutions or speak to a data solutions expert today.